
Kokiris et le monitoring
Chez Kokiris l’observabilité est un sujet de premier plan, elle nous permet d’optimiser les interventions, de limiter la durée des coupures de service et de circonscrire les incidents. L’observabilité se matérialise par le monitoring qui lui-même se subdivise en alerting et métrologie.
! Sur les captures d’écran, les informations confidentielles ont été floutées !
L’alerting
Chez Kokiris, après plusieurs années sous Shinken, nous avons choisi de migrer sous Icinga2. Icinga2 est une solution complète, modulaire et intuitive.
L’alerting est alimenté par chaque déploiement Ansible, il permet à l’équipe technique Kokiris de livrer au client un serveur totalement surveillé, conforme dans tous ses aspects à la commande passée.
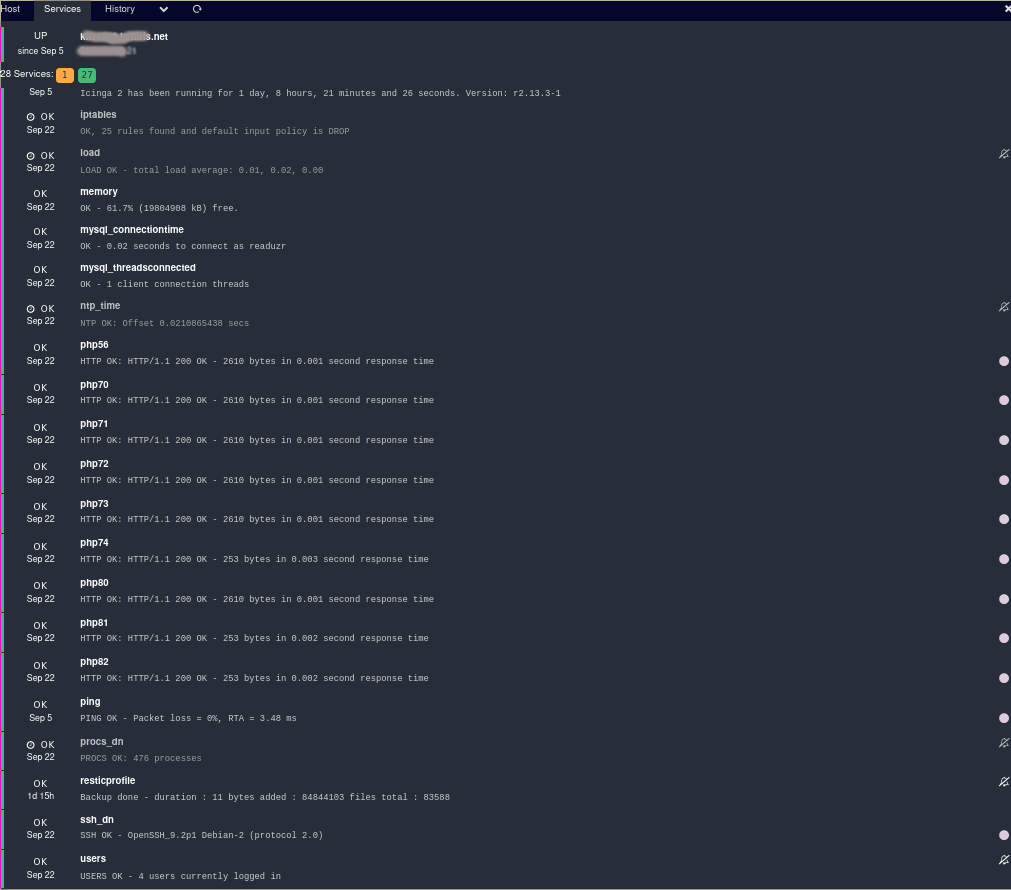
Nous surveillons peu ou prou une trentaine de points par serveur, bien entendu, la quantité de services déployés fera varier le nombre de sondes.
Echantillon de sondes déployés
Surveillance de sites clients
Nous utilisons parfois pingdom pour surveiller l’uptime de sites clients.
Pingdom étant en dehors de notre infrastructure, il nous apporte un regard « extérieur » et impartial.
Les notifications d’alerting
Comme tout système intelligent, nous ne sommes notifiés que des anomalies, la non-notification correspondant l’état fonctionnel et normal…
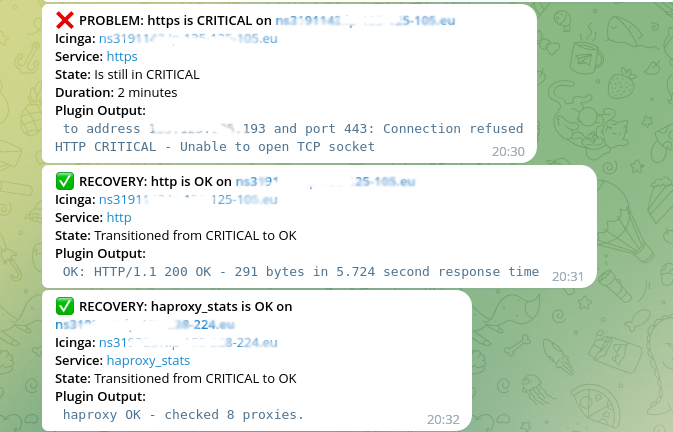
Les notifications d’alerting avertissent l’équipe technique du dysfonctionnement d’un service ou d’une anomalie dans l’élément surveillé. Chez Kokiris nous utilisons Telegram pour recevoir les notifications.
Exemple de notification
La métrologie
Précédement assurée par le couple Telegraf/InfluxDB, c’est dorénavant la stack Prometheus/Grafana épaulé par Consul qui modernise la métrologie chez Kokiris.
Avec ce système, nous sommes passés d’un mode push à un mode pull plus complexe mais aussi plus souple.
Le « scrap » de données (La récupération des métriques)
Schéma à main levée du mécanisme de découverte et de « scrapping »
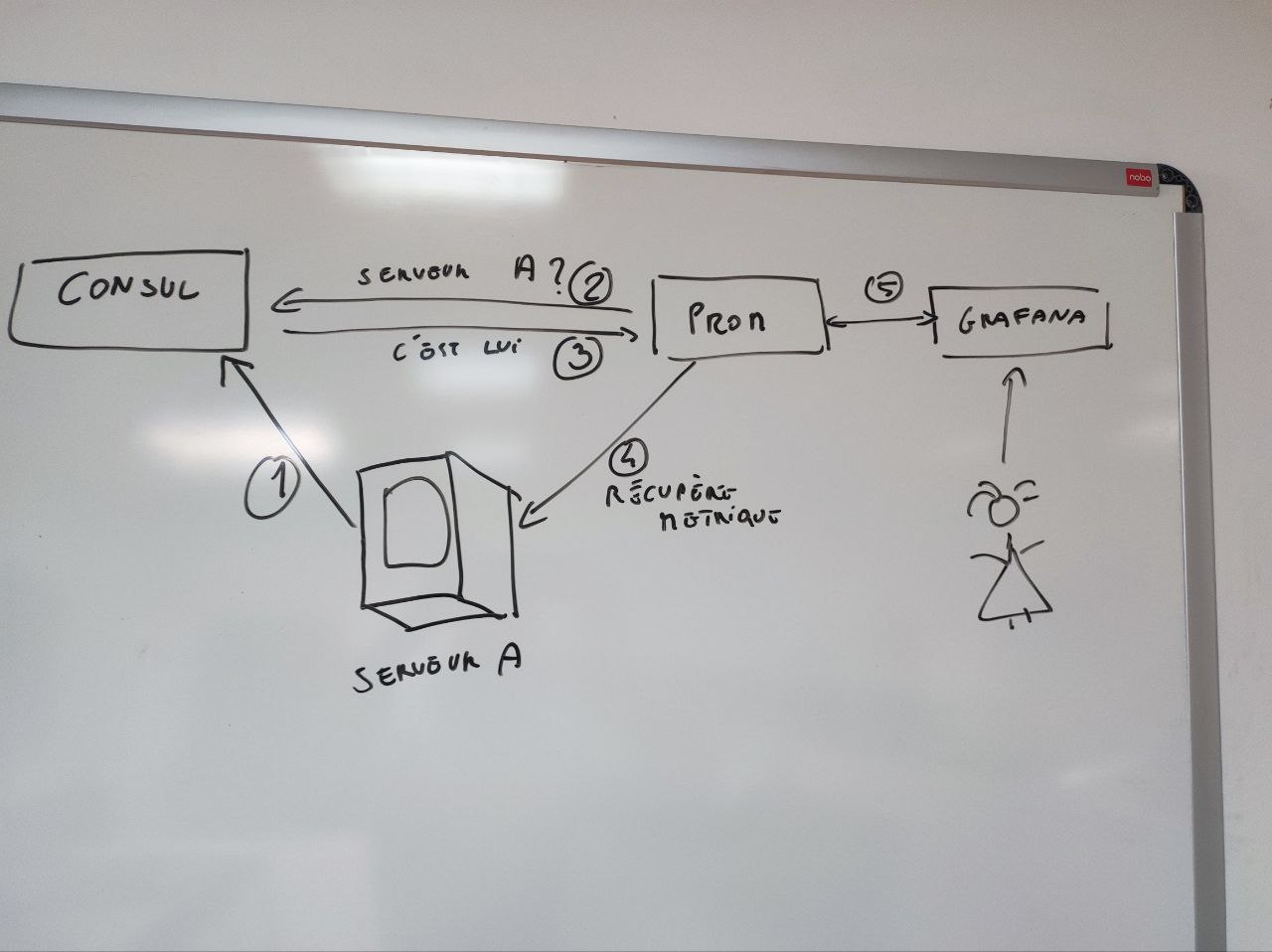
Sur chaque serveur client, tous les services surveillés sont accompagnés d’un Exporter Prometheus dédié.
Toujours sur le serveur, un agent Consul possède une définition des services et des exporter associés, définition qu’il communique à un serveur Consul, ce dernier possède alors la liste de tous les services « clients » et donc des Exporters.
Parmi ses multiples fonctions,Prometheus implémente la capacité à obtenir des « listes de service » ; nous utiliserons un de ses mécanismes : le « consul auto discovery » pour découvrir et interroger l’ensemble des exporter des serveurs clients.
Le stockage de métrique
Les métriques sont stockées sur Prometheus pendant 30 jours.
L’affichage des données de performance
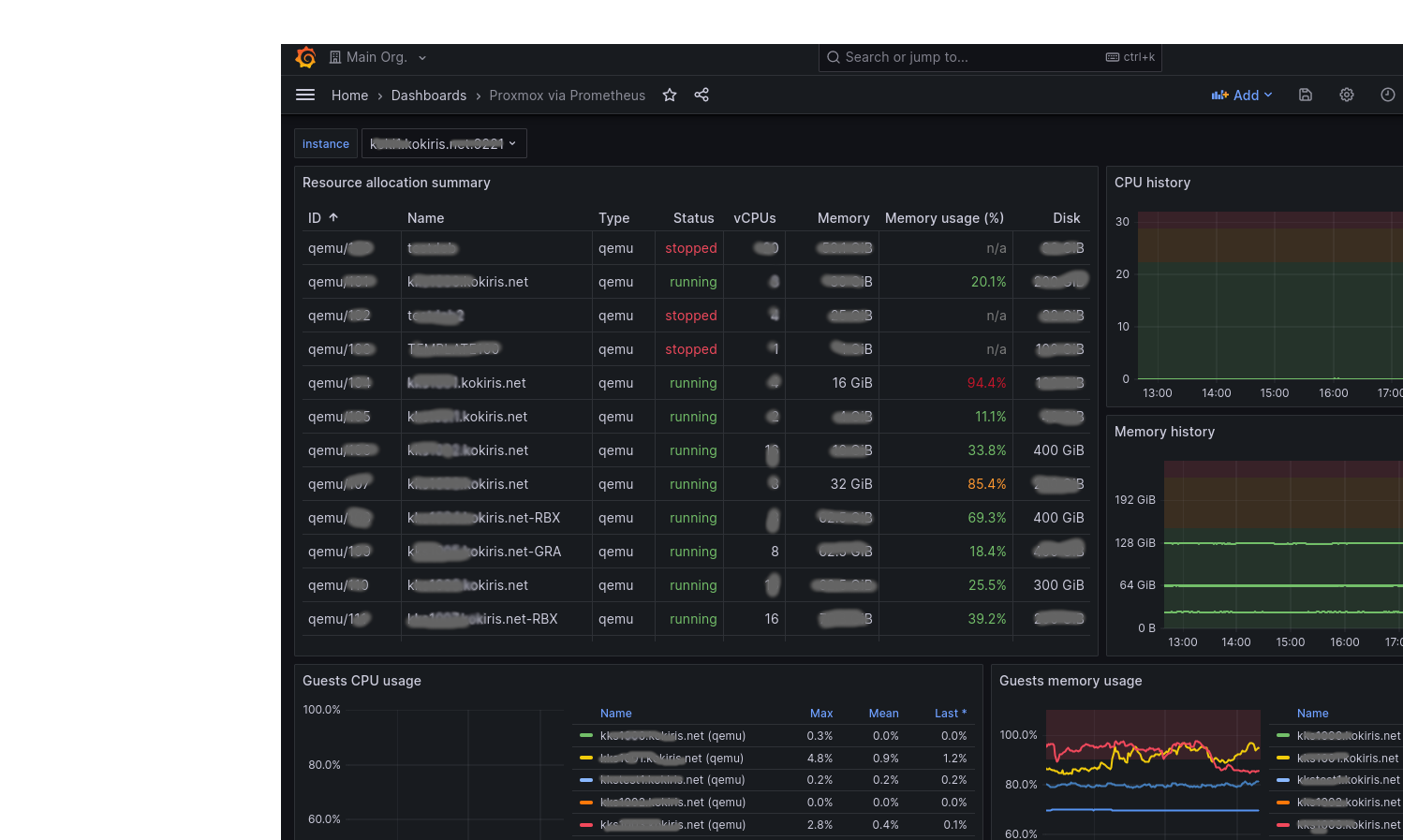
C’est Grafana qui est chargé de présenter les métriques sous forme graphique.
Exemple de dashboard pour hyperviseur
Auteur : Antonio M.